Methodology for Comparing Citation Database Coverage of Dataset Usage
Project Workflow
Project Workflow
The project workflow outlines the steps involved to evaluate how different citation databases track USDA dataset mentions in research papers. In searching for dataset mentions, the goal is to identify a set of publications that can be compared across the citation database test cases.
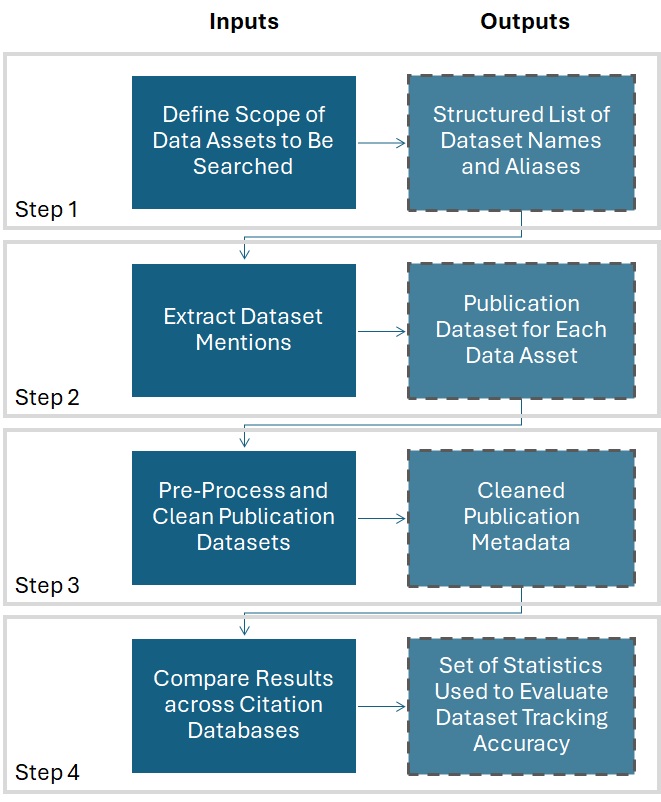
The process of deriving the list of publications from a citation database consists of four steps. Each step produces an output which is used as the input for the following step:
1. Define Scope of Data Assets to Be Searched
- Identify USDA datasets that will be searched for and tracked.
- Collect official dataset names along with common abbreviations, acronyms, and alternative references used.
Result: A structured list of dataset names and aliases.
2. Extract Dataset Mentions from Publications
- Conduct searches across citation databases using multiple methods:
- Full-Text (String) Search: Scan entire articles for relevant dataset names.
- Reference Search: Identify dataset citations within publication references.
- Machine Learning Models: Apply Kaggle competition models trained to detect dataset mentions.
Note: In cases where full-text search is not supported by the citation database API (e.g., Scopus), an initial seed corpus of publications was collected separately to train machine learning models. Refer to “Creating a Seed Corpus” for more details.
Result: Publication dataset for each data asset across each citation database.
3. Pre-Process and Clean Publication Datasets
- Pre-process and clean publication metadata generated from each citation database.
- Standardize journal, institution, and author names.
- Deduplicate records.
Result: Cleaned publication metadata, removed of duplicates, inconsistencies, and missing information.
4. Compare across Citation Databases
- Compare dataset coverage across Scopus, OpenAlex, and Dimensions.
- Apply fuzzy matching techniques to identify overlapping and unique dataset mentions.
- Analyze differences in journal coverage, citation patterns, and author affiliations.
Result: A set of statistics used to evaluate dataset tracking accuracy.